Bible Semantic Search
I love applying NLP techniques to real-world data
Introduction
A few years ago, I built a little concordance of the scriptures. It was a Similar Verse Finder, which let you search up a verse and would show you the ten most similar verses. It worked, but people often had a request:
They wanted to be able to search for their own terms.
You see, all you could do is see which verses were similar to any given verse. This was useful, but very inflexible. What if you were trying to find a scripture that you couldn't remember? This tool wouldn't help at all. A class project gave me the idea to fix it.
Background: Embeddings
I've talked about embeddings before on this blog, and I'm sure I'll talk about them again. Embeddings are a solution to the fact that computers don't "understand" the meaning of words, they only understand math. The type of embedding we're talking about today comes from a process where a model reads a chunk of text and converts it into a list of numbers called a vector. You can think of this list kind of like a numerical representation of the content.
Because LLMs are trained on massive amounts of text, they know how to assign similar numbers to similar concepts. "The dog barked" and "The puppy made a noise" will result in embeddings that are very similar mathematically. If we use this process to turn texts into embeddings, we can compare similarity in a way that allows for more robust matching than a simple keyword search.
Similar Verse Finder
So how did the Similar Verse Finder work? We used an LLM specially trained to generate these embeddings, and embedded each verse in the Bible. Then, we compared every verse to every verse (about 31,000 x 31,000 = 961,000,000 comparisons) to see which verses were closest to each other. This is pretty computationally intensive, so I did it all on my nice gaming PC at home. Then, I took the results (which verses were close to which verses) and uploaded them to the similar verse finder. Because all of the computation was done beforehand, when the user looks up a verse, no math has to happen. It had already been done
Like I mentioned above, if we wanted to let the user do their own queries, things would need to be very different. We could still pre-compute embeddings for each verse in the Bible on my computer. However, when the user wanted to search for their own query, we would need to embed it then and there. That requires either running a language model in the browser, or sending it off to a server somewhere. Then, we could compare the embedded query against all of the precomputed verse embeddings. Whichever verses had the mathematically closest embeddings would probably have the meanings most similar to the query.
Time for an Upgrade
When I first made the Similar Verse Finder, it wasn't possible to run LLMs locally in the browser. However, two big advancements have come out since then.
- Smaller, More Powerful Models: Companies are increasingly interested in creating smaller models that can run locally on consumer hardware. Models exist today that can run on a laptop or phone and outcompete any model that existed 5 years ago.
- Transformers.js: Now, there's a javascript library that lets us run small LLMs directly in the browser.
With a combination of these two advancements, the foundation now exists to build the search functionality people asked for.
Creating The Tool
So I made the tool. I started with EmbeddingGemma-300m, a new model from Google that is both small and performant. I also grabbed the King James Version text of the Bible. I chose the KJV because it is in the public domain, and because it is one of the most widely accepted Bible translations.
I re-made the Similar Verse Finder aspect of the tool, using EmbeddingGemma to embed all of the verses and compare each of them to each other. I also updated the UI to allow users (after searching for a verse) to click on a similar verse and see that verse's most similar verses. This lets users quickly chain through verses.
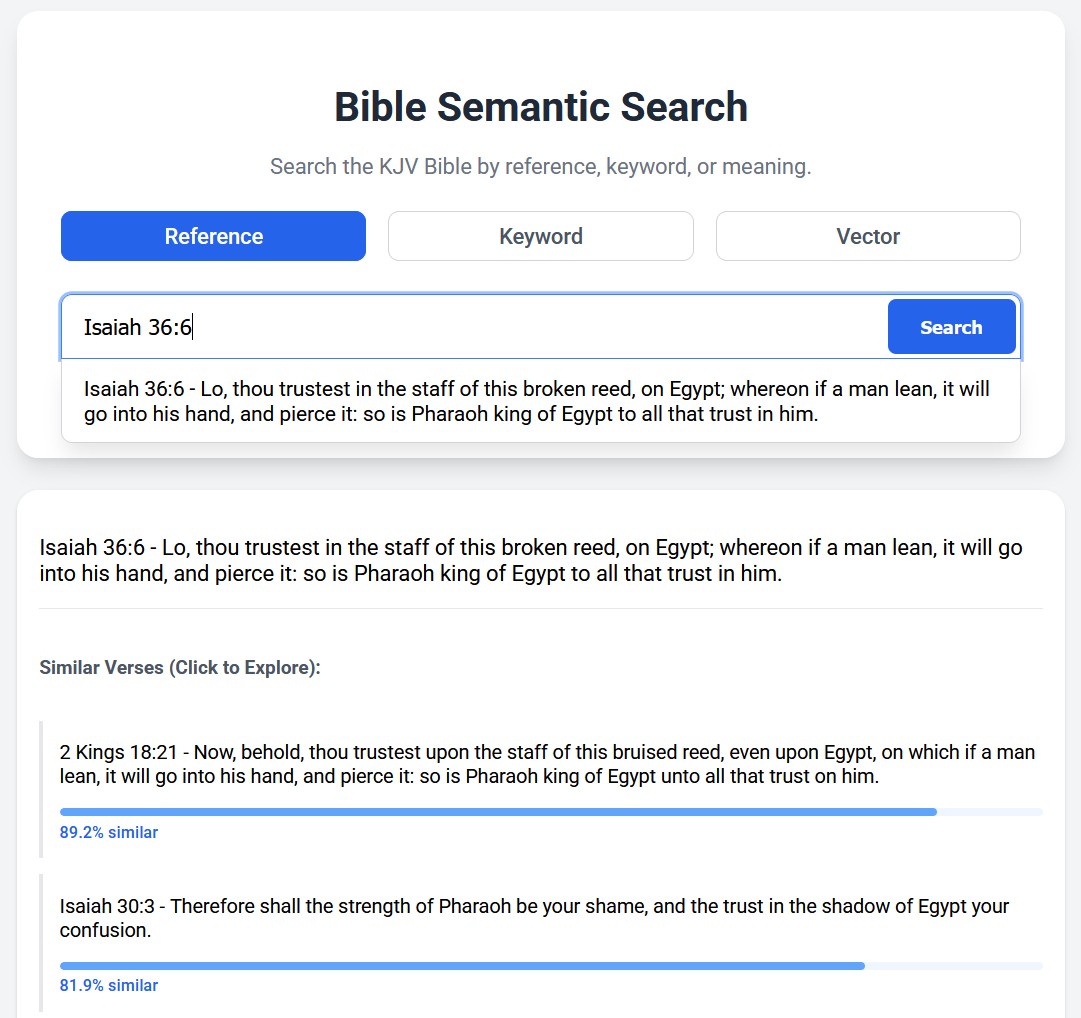
Size
Even though the model is really small for an LLM, it's still about 450 MB, which can be a lot. Since I want to be a good developer, I decided to let the users opt in to downloading this huge model. When you load the page, you can use the Similar Verse functionality (I renamed this 'Reference Search') without having to load the LLM.
I also wanted to include a traditional 'Keyword Search' functionality. To do this I use a method called TF-IDF (Term Frequency / Inverse Document Frequency). This is how most modern search systems work. I was able to create a TF-IDF index of the bible, and I did a little bit of fanciness to allow for suffixes. (For example, searching for 'Horse' can return verses about 'Horses' or 'Horsemanship' even though they're not an exact match.)
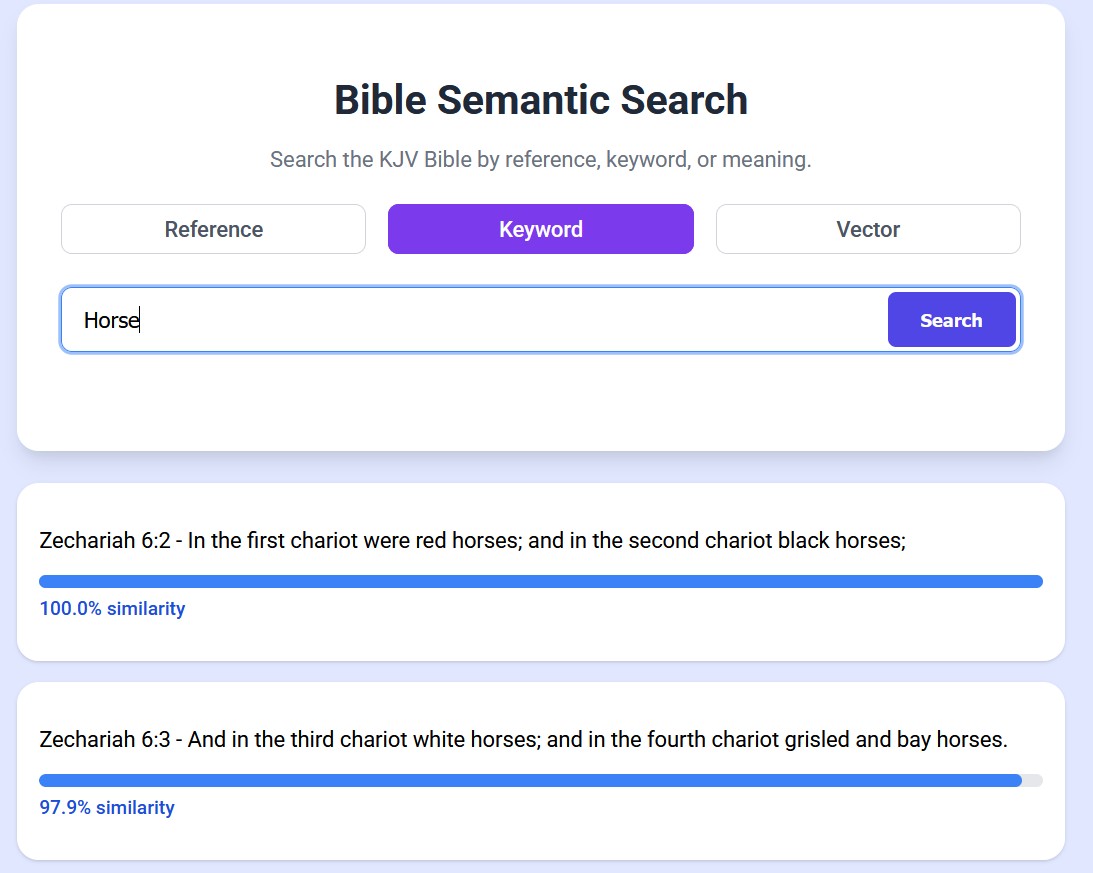
This way, people can use the tool even if they don't want to or can't download and run the language model on their device.
Uses
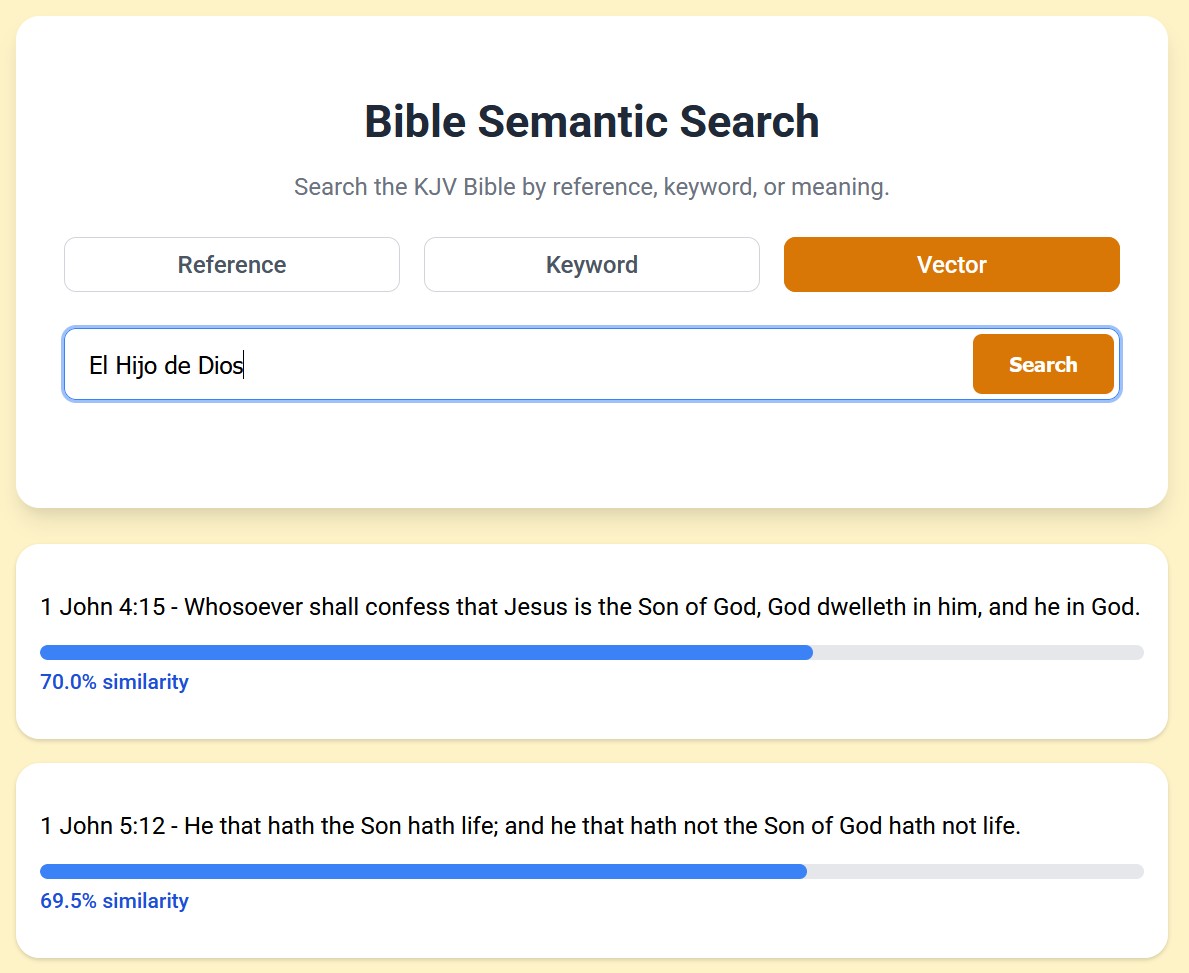
So what is this even good for? The keyword search works really well, so what does the vector search give us? First off, it lets you look for words that don't ever appear in the Bible. For example, the word 'vegetables'.
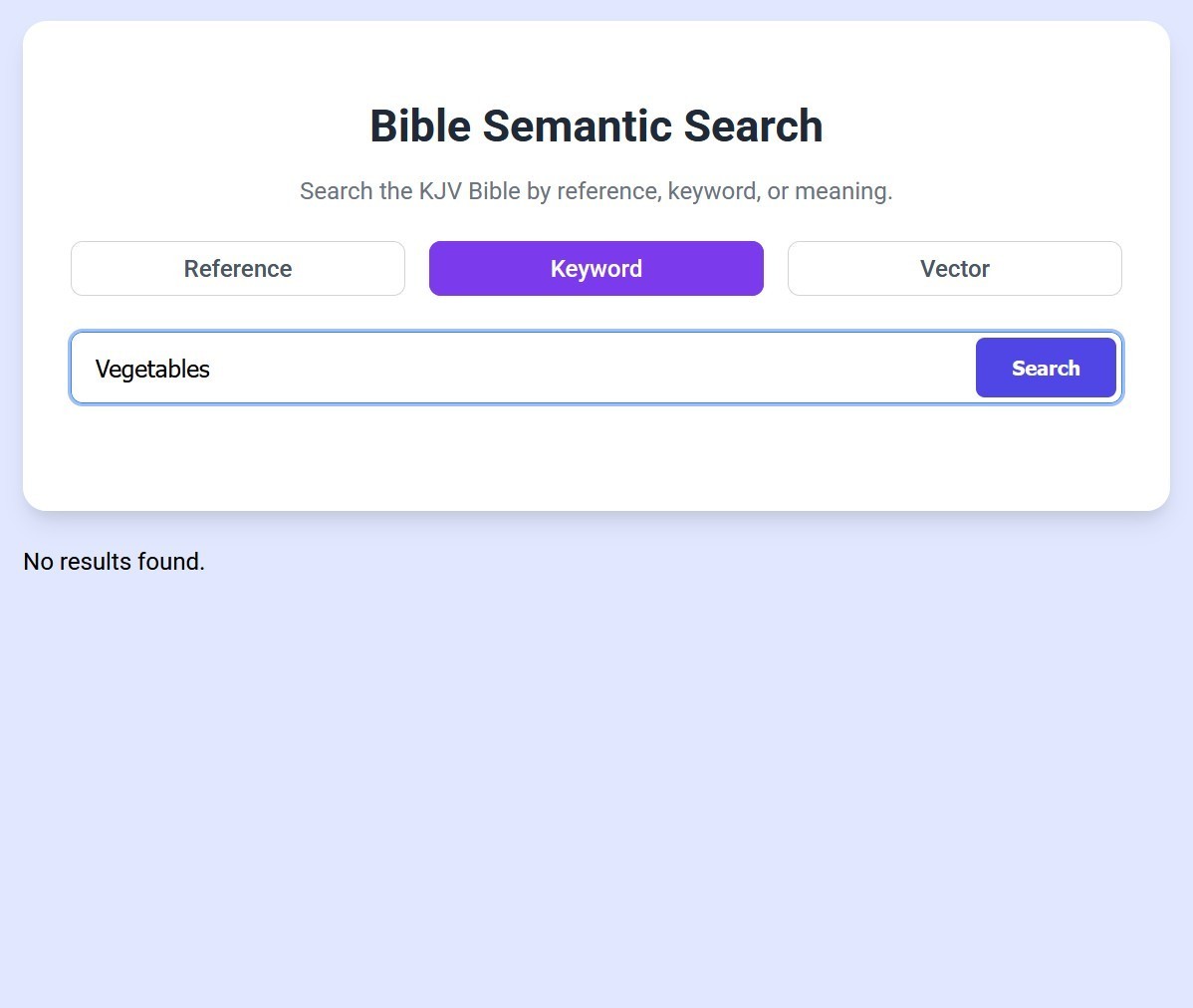

It can also help you find a verse when you can only remember the gist of it or certain aspects, even if the words don't appear in keyword searches. So if you want to look for "don't worry about the future", keyword search looks for the verse that matches all of those words best, and the algorithm gets confused. However, vector search lets you search for that meaning, and the results are much better.
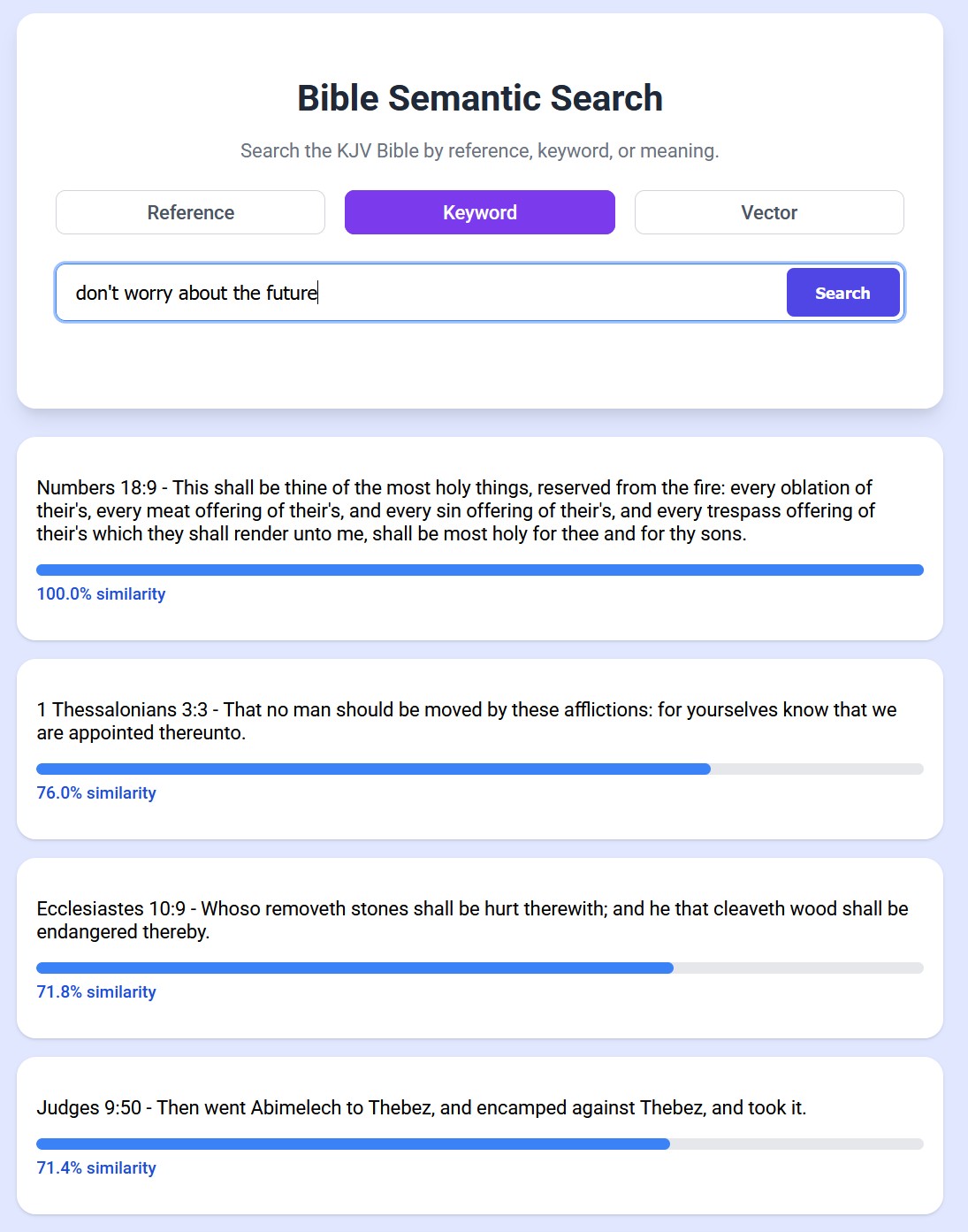

Since EmbeddingGemma was trained on over 100 spoken languages, you can even query the model in lanuages other than English and it still works!
Conclusion
Of course, the best thing to do is to try this out for yourself. One of the reasons I decided to build this was because I found out that complete strangers from the internet were using some of the Bible NLP tools I've created over the years. I love making things that people actually use. If you want to try it, I would suggest using your computer, or connecting your phone to wifi before downloading the whole vector model. So what are you waiting for? Try it out here.